
Introduction to Kafka in layman terms
Yes, you are reading yet another introduction to Kafka. Except, this time it comes from someone that have only worked with for the past two months. Since I’m new to Kafka, the confusion that I initially felt learning about Kafka is still vivid in my mind and I write this post to guide you through that
What is Kafka in the simplest sense
The definition on Kafka website reads
Apache Kafka is publish-subscribe messaging rethought as a distributed commit log.
I think this definition causes people to quickly dismiss Kafka as “just another” RabbitMQ or ActiveMQ. And this is unfortunate because Kafka architecture makes it a great deal more powerful and flexible than traditional message queues
However, for people that are not familiar with queue system, here is a basic what a basic kafka topic looks like

A topic is a list of data where producers add data to one end (back in this case) and consumers read from the other end
What does publish-subscribe means? it means systems can subscribe to a queue and get notified when new data is available
This allow the producer and consumer to be loosely coupled. If the consumer goes offline, the producer can keep adding data to the queue without worrying or even knowing about it. Vice versa, if the producer goes offline, the consumer will just wait for new data to be added.
Kafka terminologies
Along the way, I’ll introduce some Kafka terminologies so we all use the correct terms and not confused when reading the official docs
- Topic: Topic groups messages together
- Producer: Processes that push messages to Kafka topic
- Consumer: Processes that consume messages to Kafka topic
What are kafka’s differences
Kafka design of a topic is fairly simple. Each topic in Kafka can be as simple as an append-only, ordered and immutable log file where each message is written to a new line. The consumer would maintain an index to the file and will periodically ask the Kafka server for new data that arrive after its index.
Because a file in its entirety needs to fit in one server, to scale out, Kafka can maintain multiple files per topic. Consumers would maintain an last index that it has read from each partition
This design leads to couple differences:
Multiple independent consumers
I think the biggest difference that Kafka brings to the table is many consumers can read the same kafka topic independently without interfering with each other. This is in opposition to many queuing systems where if a client consume a message, it is not available to any other clients.
As mentioned above, each kafka consumer maintains its own index pointing to a position in the queue which starts at 0. It then asks Kafka to send any new messages after its current index. After processing the message, it can increase the offset so that if it crashes, it won’t have to start all over again.

This opens up many interesting use cases. For example, a queue collecting user click events can have 2 consumers: one for sending to s3 for archiving and the other one feeds into an online machine learning model to predict customers’ behavior. These 2 consumers are independent of each other and one can be slow while the other is fast. One can go down and will not affect the other.
This design implies the delivery schematic of Kafka is “At least once.” Don’t worry if it doesn’t make sense at this point. We’ll cover it in the next post
Fast
When I first said Kafka maintains a log file for a topic, I wasn’t trying to simplify it to make it easier to understand. Kafka indeed write every messages directly to file system.
Kafka also uses many optimization techniques such batching messages together and storing everything as binary. This allows it to blow competition out of the water when it comes to performance. The team that created Kafka at LinkedIn created an study comparing Kafka performance with ActiveMQ and RabbitMQ. Following are chart for performance of both producer & consumer
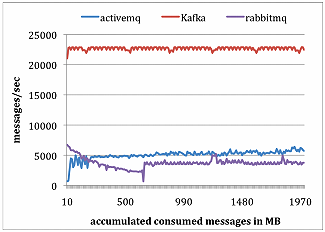
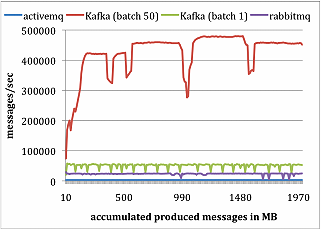
Scalable
No matter how fast kafka is, it won’t be useful if it is difficult to scale out to multiple nodes. Fortunately, Kafka was born to solve the scale problem at LinkedIn. Last September, it hits 1.1 trillion message processed per day at LinkedIn. Kafka topic can contain multiple partitions, it can span thousand of servers and have tetrabyte of data

The producer will producer messages to the topic’s partitions in a round robin fashion. As mentioned above, for each partition, the consumer will maintain an index of its last read item. Periodically, it’d ask Kafka for any new data and will receive messages as the partition is ready to return them. This implies that for multiple partitions topic, consumers can receive message out of order. We will go over more detail in the next post
Durable
The kafka broker writes messages are written to disk shortly receiving them. But you can still lose them if that server crashes, can’t you?
That’s when replication comes into play. By default, each partition has a replication factor of 1, which means no replication. By setting it to 2, Kafka will replicate the partition to another broker. Once the data is replciated, we have access to it even if we lose the first server
When you have a replicated partition, one of them will serve as a leader and all reads & writes will go to that leader. Kafka also maintains a list of in-sync replicas or ISR which is the number of replicas that have caught up with the leader. There are 3 form of publishing messages to kafka with different levels of performance and durability
- Not waiting for acknowledgement. The producer will continue without waiting for any form of acknowledgement. This is the fastest but also has the highest chance of data loss
- Waiting for acknowledgement from the leader. The producer will wait until the leader commits the message to its log but before replicating it to all other replicas. You will lose the message without knowing if the server goes offline after it has sent the ack but before replicating
- Waiting for acknowledgement from all in sync servers. This is the most durable but also the slowest
Conclusion
I hope this post gives you an overall introduction to Kafka and its strengths and weaknesses. In short, Kafka is indeed a pubsub system with a very particular design that make it excel in certain tasks. Kafka is really good at ingesting a insane amount of data quickly and make it available to thousands of independent consumers. However its design bring with its certain gotchas that can hinder people working with it for the first time. I’ll cover them in more details in the next post
Trackbacks & Pingbacks
[…] my first post, I’ve shown how simple Kafka is. Nevertheless, to be fast, durable and scalable, Kafka has […]
Leave a Reply
Want to join the discussion?Feel free to contribute!